เริ่มต้นใช้ AWS Amazon S3 – Storage
S3 เป็นชื่อ Storage service ของ AWS เป็นเครื่องมือที่ใช้ง่าย ทำความเข้าใจง่าย และมีโอกาสได้ใช้บ่อยมาก วันนี้มาทำความรู้จักกัน
S3 Storage หรือ ชื่อจริงคือ Amazon S3 เป็นพื้นที่สำหรับเก็บ Object ต่างๆ ซึ่งพื้นฐานง่ายมาก คือ เราจะต้องสร้าง ‘bucket’ หรือ ถัง ขึ้นมาเพื่อใช้เก็บก่อน แล้วเราก็ค่อยเอา object ของเราเข้าไปเก็บในนั้น แล้วเวลาเรียกใช้ ก็เรียกผ่าน URL ก็ได้ หรือ เราจะเก็บไว้เป็นแบบส่วนตัวไม่ให้เปิดผ่าน URL ก็ได้เช่นกัน
สร้าง S3 bucket
หลังจากที่เราเข้ามาที่ S3 แล้ว (วิธีการเข้า กด ที่เมนู Services ที่ด้านซ้ายบนของหน้า console แล้วเลือก S3) กดปุ่ม Create bucket
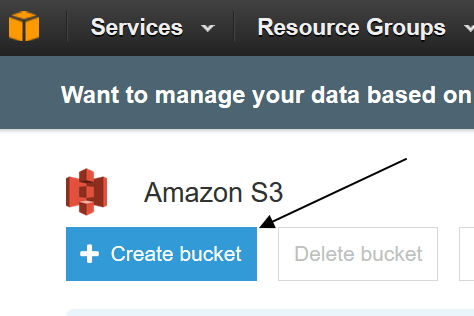

จากนั้นตั้งชื่อ bucket อันนี้จะไปปรากฏอยู่ใน URL เวลาที่เรา share ด้วยนะครับ ดังนั้น ตั้งให้อ่านง่าย สั้นๆ จะดีที่สุด และต้องไม่ซ้ำกับที่เคยมีอยู่ (ทั้งของเราและคนอื่น) และอีกหัวข้อจะเป็น Region ซึ่งมันคือ พื้นที่เก็บไฟล์ที่ประเทศไหน โซนไหนนั่นเอง เรื่อง Region นี้ มีผลต่อความเร็วในการเข้าถึง เช่น อยู่ไทย แต่สร้างที่ Virginia ก็จะช้า ต้องสร้างที่ Singapore จะเร็วสุด แต่แน่นอน ว่าราคาแต่ละ region ไม่เท่ากันครับ (กรณีที่ใช้เกิน free tier)
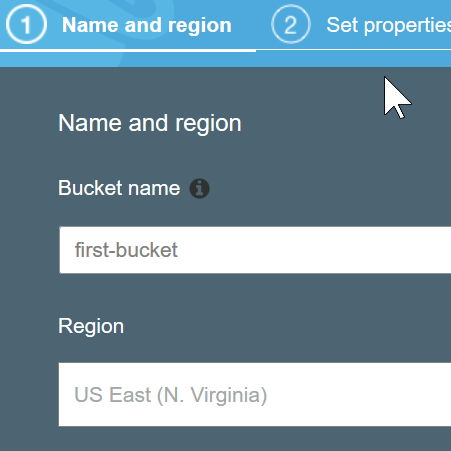

หน้าจอต่อมาคือการกำหนดคุณสมบัติของ bucket ซึ่งมีสามหัวข้อ ดังนี้
1. Versioning ให้ระบบจดจำหากมีการ upload file ใหม่ขึ้นมาทับในชื่อเดิม มันจะมองว่าเป็น version ใหม่ แล้วเราสามารถเรียก version เก่าขึ้นมาได้ (ปิดโดยอัตโนมัติ)
2. Logging ให้ระบบบันทึกข้อมูลการเรียกใช้เอาไว้ ว่ามีการเรียกไฟล์ไหนมาเมื่อไร หรือมันคือ access log นั่นเอง ไม่มีค่าใช้จ่ายเพิ่มเติมสำหรับการ logging เว้นแต่ storage ที่เอาไว้เก็บ log file พวกนั้นเท่านั้น (ปิดโดยอัตโนมัติ)
3. Tags อันนี้ ให้เรา tag ว่า bucket นี้มันคืออะไร เดี๋ยวจะอธิบายเรื่อง tag เอาไว้ด้านล่าง (คนใช้ free tier ข้ามไปได้เลย ไม่สำคัญ มันเอาไว้ใช้ประโยชน์ตอนโดน charging เยอะๆ ในหลายๆงาน)
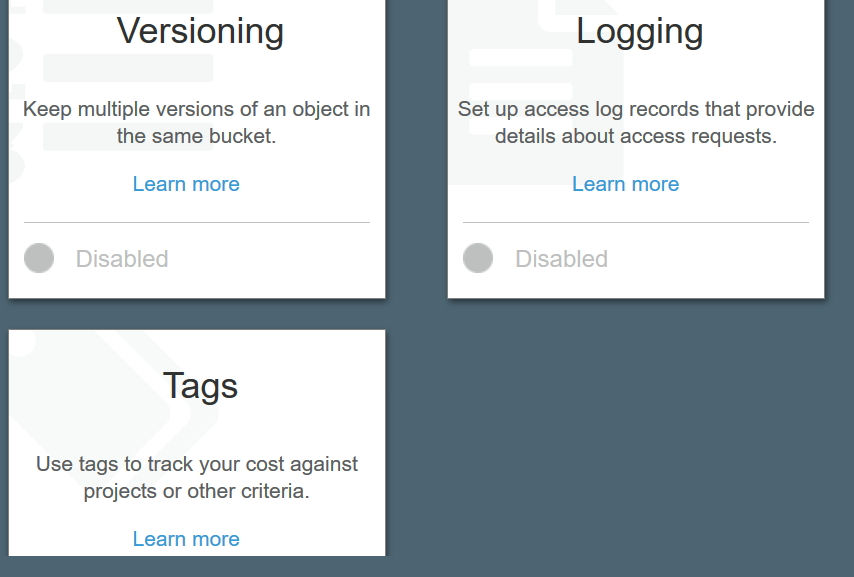

หน้าจอต่อมาคือ การจัดการ permission โดยปกติเราจะไม่เปลี่ยนอะไร เพราะว่ามันจะตั้งค่าให้เรามีสิทธ์แก้ไขได้ แล้ว ห้ามคนอื่นที่ไม่ได้รับอนุญาต เข้ามาแก้ไข และสำหรับคนที่เปิด logging เอาไว้ ก็ต้องให้ Log Delivery read write ด้วยนะครับ ไม่อย่างนั้นจะเขียน log ให้เราไม่ได้

หน้าจอสุดท้ายก็คือการ review ก่อนการสร้างจริง ไม่มีอะไรมาก ก็กด Create Bucket ได้เลย


ระบบจะพากลับมาหน้าจอ bucket list ซึ่งจะมี bucket ที่เราสร้างเอาไว้เมื่อสักครู่นี้ปรากฏอยู่แล้ว

จากนั้นเรามาเริ่ม upload file ใส่กันเลยดีกว่า ให้เราคลิกเข้าไป แล้วกด upload ได้เลย หรือจะสร้าง folder ก็ได้


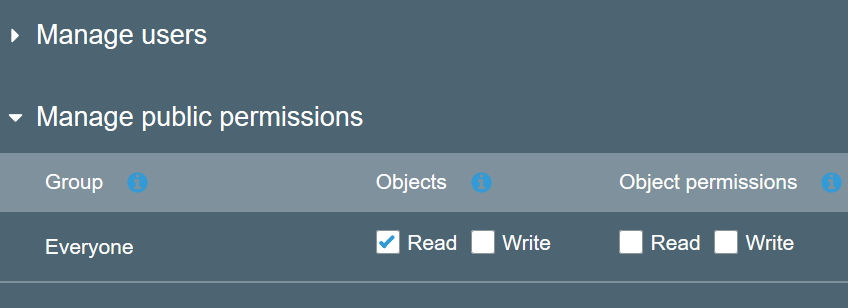
ในขั้นตอนการสร้างนี้ ระบบจะถามเราเรื่อง permission อีกครั้ง ถ้าเราอยากเปิดให้คนอื่น download ก็ขอให้กด เลือก public permission มีสิทธ์ read ที่ object อย่างเดียวเท่านั้น นะครับอีกอันจะเป็นการปรับหรือดู permission ของ object ครับ

Storage class อันนี้คือตัวที่บอกว่า ไฟล์นั้นมีพฤติกรรมอย่างไร แนะนำ standard ครับ ส่วน standard IA นั้น เอาไว้เก็บไฟล์ที่มีการเรียกใช้น้อยมาก เน้นเก็บนานๆ หรืออาจจะไม่ได้เรียกใช้เลย แบบนี้มันจะคิดค่าใช้จ่ายที่ถูกกว่าแบบ standard ครับ แต่ว่า ถ้าเราเรียกใช้ไฟล์ เราจะมีค่าใช้จ่ายในการเรียกด้วยนะครับ ตามขนาดไฟล์ที่เรียกขึ้นมา ซึ่งแบบ standard ไม่มี ดังนั้น ต้องคิดดีๆครับ ส่วน reduce redundancy storage นั้นการทำงานจะเหมือน standard แต่ต่างตรงที่ ไม่เน้น ความเสถียรที่ไฟล์จะคงอยู่ตลอดไป 99.999999999% เหมือนอย่างที่ standard ทำได้ แต่จะรับประกันแค่คงอยู่ 99.99% เท่านั้น (จริงๆมันก็มากพอแล้วนะ) โดยการเก็บแบบนี้ บาง region จะคิดราคาถูกกว่า standard แต่บาง region ก็แพงกว่า ดังนั้น เลือกกันดีๆ
Encryption ก็เอาไว้เข้ารหัสไฟล์ ที่เก็บลงไปใน S3 อันนี้คือ low level นะครับ คือ เมื่อเราเข้ารหัส เราก็จะยังสามารถเปิดไฟล์ได้ปกติ แต่กระบวนการเข้ารหัส ถอดรหัสนั้นเป็นหน้าที่ของ S3 เอง เพื่อให้มั่นใจว่า ถ้ามีใครเข้าถึง hardware ที่ใช้เก็บข้อมูลเราใน S3 ก็จะไม่สามารถอ่านข้อมูลได้ตรงๆ ต้องถอดรหัสไฟล์ให้ได้ก่อน โดยตัวเลือก ก็จะมี แบบไม่เข้ารหัส เก็บตรงๆเลย หรือ S3 master-key อันนี้เป็น key ที่ S3 เค้าบริหารจัดการให้ และมีการ rotate เป็นระยะเพื่อความปลอดภัยด้วย ส่วน KMS master-key นั้น จะเป็นอีกบริการหนึ่ง คือบริการ บริหารจัดการ secret key ซึ่งอันนี้ก็จะมีค่าใช้จ่ายในส่วนบริหารจัดการนี้เพิ่มเติมด้วย แต่เราสามารถบริหารจัดการได้อย่างที่เราต้องการเลย จะ rotate บ่อยแค่ไหน จะเลือก encrypt อะไร ก็ตามใจเราครับ


กว่าจะ upload ได้ไฟล์ เล่นเอาเหงื่อตก แต่จริงๆแล้ว เราไม่ต้อง review ก็ได้นะครับ browse file แล้ว upload ขึ้นมาได้เลย ทั้งหมดนี้เป็นรายละเอียดที่เรากำหนดได้นั่นเอง
เมื่อเรา upload แล้ว ให้เราคลิกดูที่ไฟล์ แล้วเราก็จะพบ url ที่ใช้เปิดบน browser ได้ ตัวอย่างเช่น https://s3-us-west-2.amazonaws.com/bee-first-bucket/thinkstats2.pdf จะเห็นว่ามีชื่อ bucket เราอยู่ในนั้นด้วยนั่นเอง
และเราสามารถเอา css file , js file มา upload ไว้ที่ s3 แล้วก็เอา URL ไปใส่ใน html code ได้เลยนะครับ (ต้องไม่ลืมตั้ง permission ให้ถูกต้องด้วยนะ คือ public read) แต่ S3 storage นี่ ไม่ใช่ CDN นะ ดังนั้นอย่าสับสน เพราะถ้าเราเก็บไว้ที่ region ไหน มันก็จะเก็บอยู่ที่ region นั้น และดึง data ออกมาจาก region นั้นเสมอ
การประยุกต์ใช้ S3 storage
เอามาทำหน้าเว็บก็ได้ เพียงแค่เราเอา image , css ,js ,html file วางใน bucket ทั้งหมด เราก็สามารถได้หน้าเว็บ static โดยไม่ต้องสร้าง server แล้ว!
เอามาเก็บ config file หลายๆงานที่ใช้ AWS service เราสามารถให้ program เข้ามา read ได้ โดยตั้ง permission เพื่อให้ app/service เหล่านั้นเข้ามาใช้งานได้ แต่ไม่ตั้ง public แค่นี้เราก็บริหารจัดการ config file ได้อย่างง่ายแล้ว
storage สำหรับ generate ไฟล์เพื่อให้ download กรณีนี้มักถูกใช้ ในงานประเภทที่สร้างไฟล์มาแล้วถูก download สูงๆ ถ้าเราเก็บไฟล์ไว้ใน server เวลามีคน download server ก็จะต้องเสียพลังงานเพื่อประมวลผลและรองรับงาน download เหล่านั้นด้วย ดังนั้นเราปล่อยให้เป็นหน้าที่ S3 เลยดีกว่า
ค่าใช้จ่าย AWS S3 Storage
S3 มีการเก็บค่าใช้จ่ายหลักๆ สามเรื่อง คือ จำนวนครั้งในการเรียกใช้ , พื้นที่ที่ใช้เก็บ และ bandwidth ที่เสียไป เช่น การ upload เข้ามา (เรียกว่า PUT) หรือ download หรือเอาไปแสดงผล (เรียกว่า GET) เหล่านี้ จะถูกคิดเงินทั้งหมด แต่สำหรับ free tier ที่ใช้งานนั้น จะให้เราใช้ได้ดังนี้
– 5 GB of Standard Storage
– 20,000 Get Requests
– 2,000 Put Requests
– First 1 GB / month data transfer
หรือ อธิบายก็คือเก็บไฟล์ได้ 5GB ถูกโหลดได้ไม่เกิน 20000 ครั้งต่อเดือน upload/copy ไฟล์ได้ไม่เกิน 2000 ครั้งต่อเดือน และ download ผ่าน internet ได้ไม่เกิน 1GB ต่อเดือนนั่นเอง
คิดว่า น่าจะเข้าใจกันมากขึ้นแล้ว สำหรับการใช้งาน S3 Storage ขอให้ลองใช้งานกันเอง เพื่อที่จะได้เข้าใจมากขึ้น อย่างตัวอย่างที่ยกให้ดู S3 มันไม่ได้เอาไว้เก็บไฟล์เหมือนอย่าง cloud backup แบบอื่น แต่มันสามารถเอามาประยุกต์ใช้งานได้หลายรูปแบบเลย
Tags ใน AWS คืออะไร แล้วมีประโยชน์อย่างไร
ที่ติดเอาไว้ในด้านบนเรื่องของ tags ใน AWS อธิบาย เพิ่มคือ ใน service เกือบทุกอย่างของ AWS จะรองรับการ Tags เอาไว้ โดยให้เราตั้งค่าได้เอง ว่าเราจะตั้ง tag ชื่ออะไร และ มีค่าเป็นอะไร สำหรับประโยชน์หลักๆ เอาไว้แยกค่าใช้จ่าย เพราะว่าคนที่ใช้ AWS หนักๆเนี่ย มันจะถูกรันงานด้วยรูปแบบที่หลากหลายมากๆ เช่น งานส่วนHR , Financial เป็นต้น อะไรเหล่านี้ เวลาทำ cost มันจะยากมาก ถ้าเราไม่ tag เอาไว้ เพราะว่าสิ้นเดือนปุ้บ รวมมาเป็นก้อนเดียว ยากเลย แต่จริงๆ แม้ว่าเราทำ tags แล้วก็ตาม มันก็ยังรวมมาเป็นก้อนเดียวอยู่ดีนะ แต่ว่าเวลาเราสืบค้นย้อนหลัง เราจะอาศัย tags เป็นตัวซอยค่าใช้จ่ายออกมาได้อีกที แต่มันก็จะมีบางอย่างที่เรา tag ไม่ได้ เช่น bandwidth ที่ใช้ อันนี้ยากเลย เพราะมันคือเป็น bandwidth รวมของแต่ละ regions เท่านั้น